Efficient Fine-Tuning
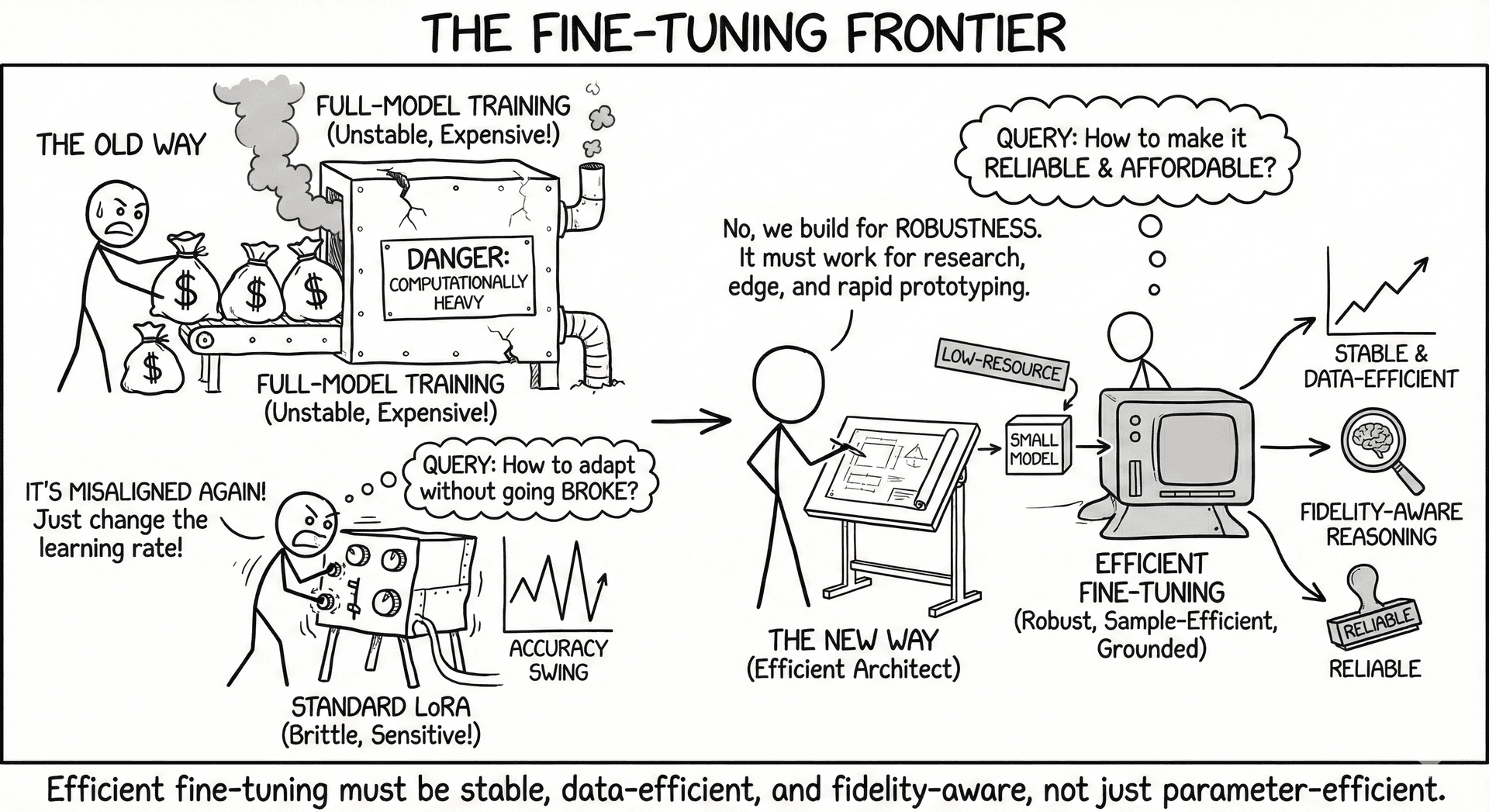
Efficient fine-tuning asks a simple question: How do we adapt large models without paying large-model costs? As LLMs scale, full-model training becomes impractical, and even standard PEFT methods like LoRA can be brittle, sensitive to hyperparameters, or misaligned with downstream reasoning demands. Our work pushes PEFT toward robustness, sample efficiency, and theoretical grounding, showing how fine-tuning can be made reliable even for small models and low-resource settings.
Why We Need Efficient Fine-Tuning
- Full-parameter fine-tuning is unstable and computationally heavy.
- Standard LoRA can swing wildly across learning rates and batch sizes.
- Many PEFT methods improve accuracy but distort reasoning or introduce variance.
- Fine-tuning must remain affordable for research groups, edge deployment, and rapid prototyping.
Efficient fine-tuning must therefore be stable, data-efficient, and fidelity-aware, not just parameter-efficient.
How Our Works Connect the Dots
-
ID3 Shows that parameter selection remains very crucial for task-specific knowledge adaptation. Rather than chosing suboptimal set of pre-determined parameters, ID3 advocates for adaptive parameter selection strategy for efficient fine-tuning.
-
MonteCLoRA (Bayesian LoRA) Reveals that LoRA’s brittleness comes from deterministic low-rank updates. By injecting structured Monte Carlo noise, MonteCLoRA produces smoother loss landscapes, lower variance, and more reliable convergence—all while keeping LoRA’s parameter budget.
Together, these works redefine efficient fine-tuning as robust adaptation rather than simply “fewer trainable parameters.”
Practical Guide — When to Use Which Method?
- If LoRA is unstable or sensitive to hyperparameters → Use MonteCLoRA for smoother optimization.
- If you need small models to reason better without large budgets → Use ID3 + PEFT for efficient performance lift.
- If you want a PEFT method that generalizes reliably across tasks → Use MonteCLoRA for robustness under noise.
Big Picture
Efficient fine-tuning is no longer just about minimizing parameter counts—it is about designing adaptive, stable, and trustworthy mechanisms for injecting new capabilities into LLMs. Our work shows that with principled noise modeling and intelligent data construction, small updates can produce big, reliable gains, democratizing model adaptation across the entire LLM ecosystem.