Model Compression
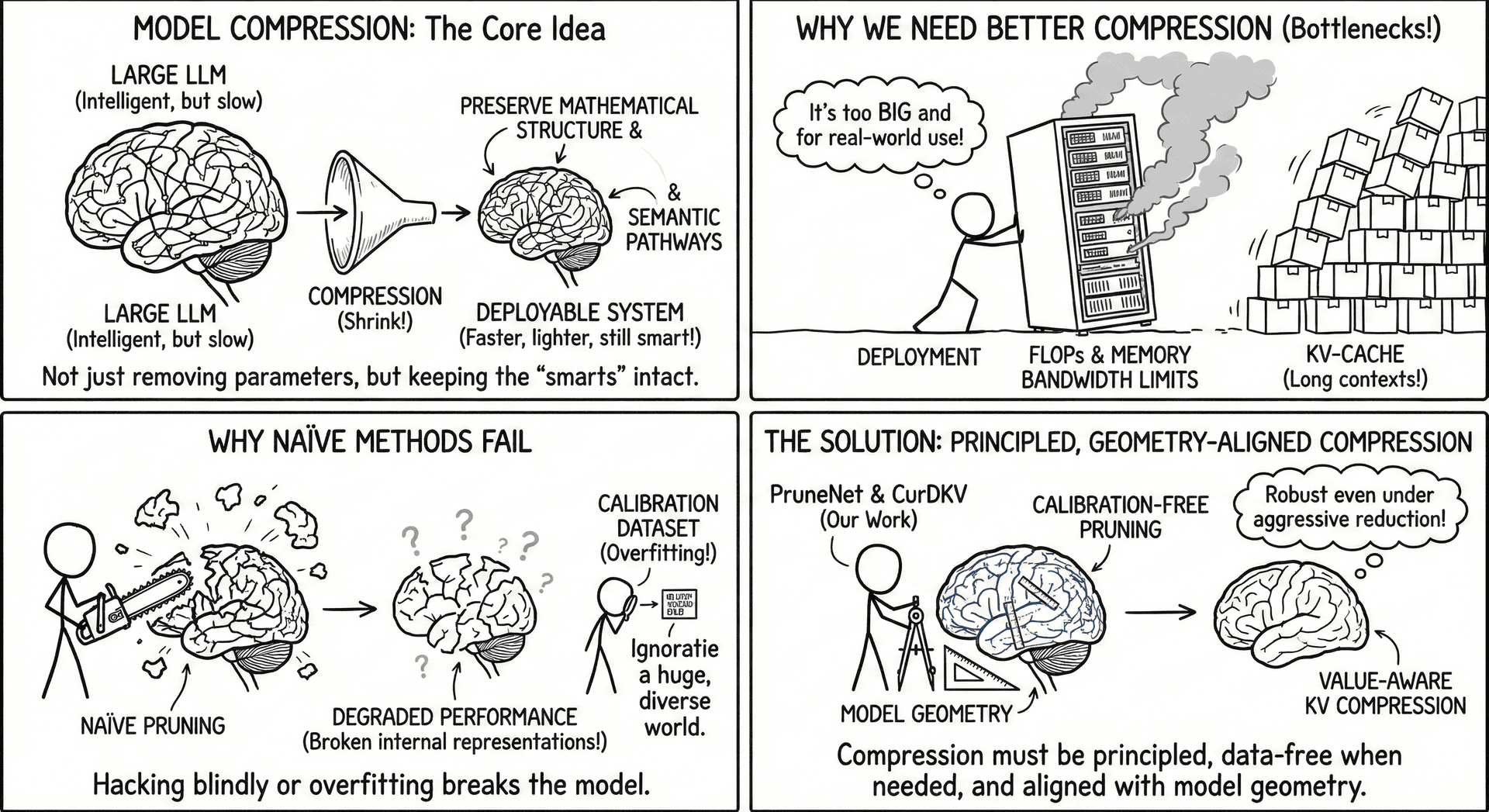
Model compression aims to shrink large language models into faster, lighter, deployable systems—without discarding the behaviors that make them intelligent. Our work shows that effective compression is not just about removing parameters: it requires preserving the mathematical structure and semantic pathways through which models reason. PruneNet and CurDKV embody this philosophy, offering calibration-free pruning and value-aware KV compression that remain robust even under aggressive reduction.
Why We Need Better Compression
- As context lengths and model sizes grow, the bottleneck shifts: FLOPs, memory bandwidth, and KV-cache all limit real-world deployment.
- Naïve pruning or key-only heuristics break internal representations, degrading performance long before theoretical sparsity limits.
- Existing methods overfit to calibration datasets or rely on attention scores that poorly reflect actual importance.
Compression must therefore be principled, data-free when needed, and aligned with model geometry.
How Our Works Connect the Dots
-
PruneNet — Calibration-Free Structured Pruning, Recasts pruning as policy learning: instead of scoring parameters with data-dependent heuristics, PruneNet learns a reusable pruning policy driven by spectral preservation. By minimizing KS distance between singular value distributions of original and compressed matrices, it maintains the model’s representational backbone—achieving high sparsity with minimal accuracy loss and near-optional recovery finetuning.
-
CurDKV — Value-Guided KV Compression, Challenges the attention-score paradigm by showing that preserving V (values) is crucial for maintaining semantic content. CurDKV approximates CUR decomposition with lightweight Gaussian projections, selecting tokens by combined key–value leverage scores. This produces KV caches that retain meaning even under 70–90% eviction, outperforming attention-only baselines on LongBench and Ruler.
Together, these works elevate compression from removing things cheaply to preserving the right things intelligently.
Practical Guide — When to Use Which Method?
- If pruning whole layers/neurons with no calibration data → Use PruneNet for spectral fidelity and reusable pruning policies.
- If compressing KV for long-context inference → Use CurDKV or AdaCurDKV to retain semantic value paths.
- If targeting high sparsity with minimal recovery finetuning → PruneNet performs reliably even at 20–40% compression.
- If dealing with NIAH or retrieval-heavy workloads → CurDKV offers superior robustness under aggressive eviction.
Big Picture
Model compression is evolving from heuristics to geometry-aware, value-aware, and data-independent methods. PruneNet and CurDKV show that respecting a model’s internal structure—its spectrum, its value flows, its hidden semantics—is the key to building compressed LLMs that are not just smaller, but still smart. These approaches pave the way for resource-efficient models that operate comfortably on long contexts, edge hardware, and real-time applications.