Efficient Inference
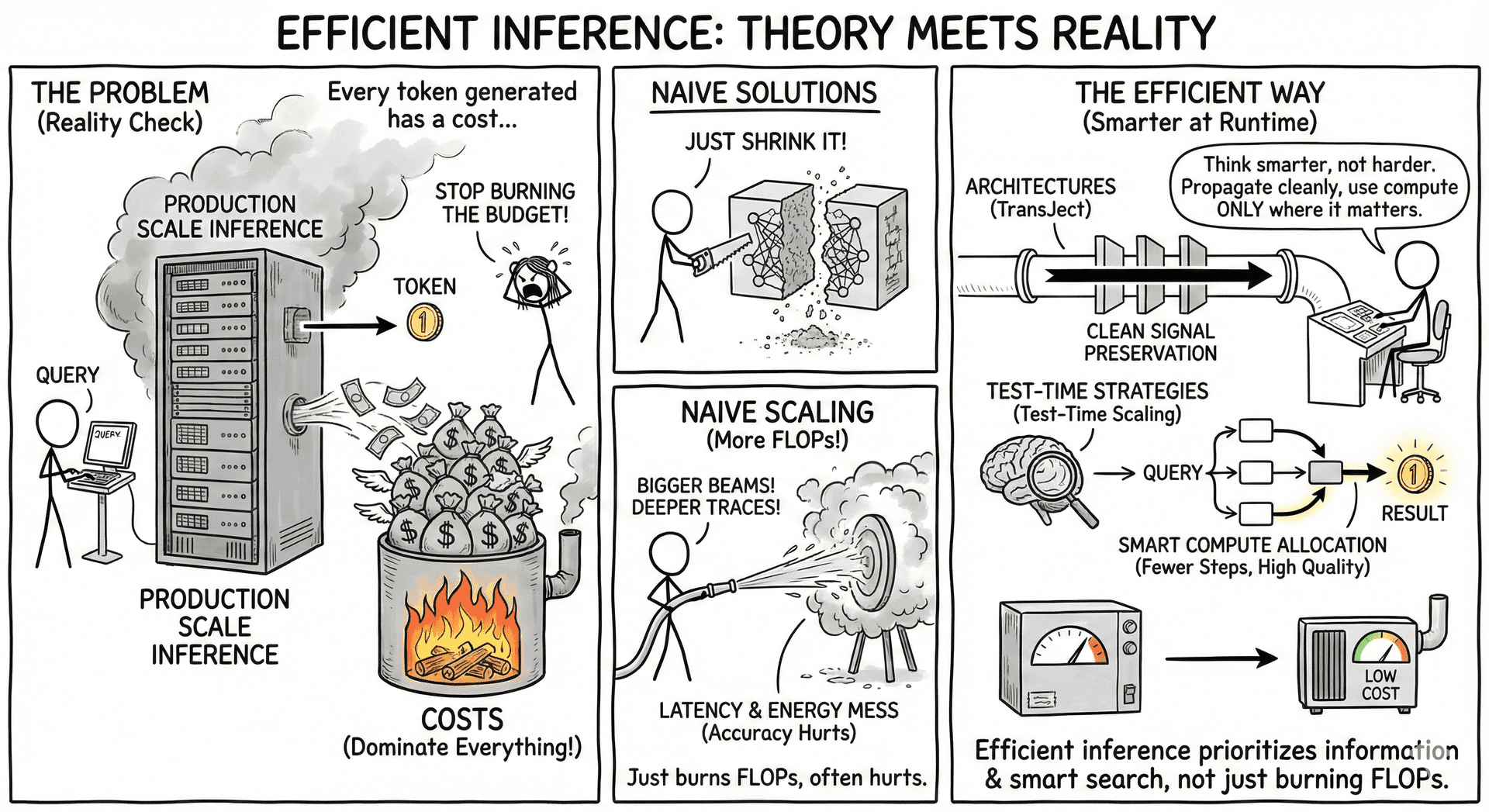
Efficient inference is where theory meets reality: every token generated has a cost, and at production scale those costs dominate everything else. Instead of making models smaller, efficient inference focuses on making them smarter at runtime—propagating information cleanly, thinking with fewer steps, and using compute only where it matters.
Our work in this theme connects two complementary directions: architectures that preserve signal across depth (TransJect), and test-time strategies that maximize reasoning quality per unit of compute (Test-Time Scaling).
Why We Need Efficient Inference
- Inference is the bottleneck for deployment—every user query triggers real-time computation.
- Long-context attention and deep stacks amplify latency, memory pressure, and energy use.
- Naively scaling inference (more tokens, deeper traces, bigger beams) often hurts accuracy despite increasing cost.
Efficient inference must therefore prioritize information preservation, compute allocation, and search strategies that actually improve reasoning instead of just burning FLOPs.
How Our Works Connect the Dots
-
TransJect — Manifold-Preserving Transformers, Shows that the core bottleneck in deep inference is geometric distortion: representations drift, entropy increases, and gradients vanish through depth. By enforcing injectivity and spectral structure, TransJect maintains stable signal propagation, enabling deep encoders to operate efficiently on both short and long sequences with lower entropy and faster inference.
-
The Art of Test-Time Scaling Reveals that inference-time heuristics (beam search, thinking longer, exploring wider) can easily become anti-scaling—compute increases but accuracy drops. The paper establishes when and why inference-time methods help, and provides a principled framework for composition, early-stopping, and verification-based scaling that improves reasoning quality per token.
Together, they highlight a unifying message: efficient inference is not about doing less, but about doing the right compute at the right locations in the model and the right moments during generation.
Big Picture
Efficient inference is the design principle that makes large models usable at scale. By preserving structure within the model (TransJect) and optimizing structure outside the model (test-time scaling), our work demonstrates that inference can be both faster and smarter—a critical step toward deployable, reliable, and cost-effective LLM systems.