Efficient Architectures
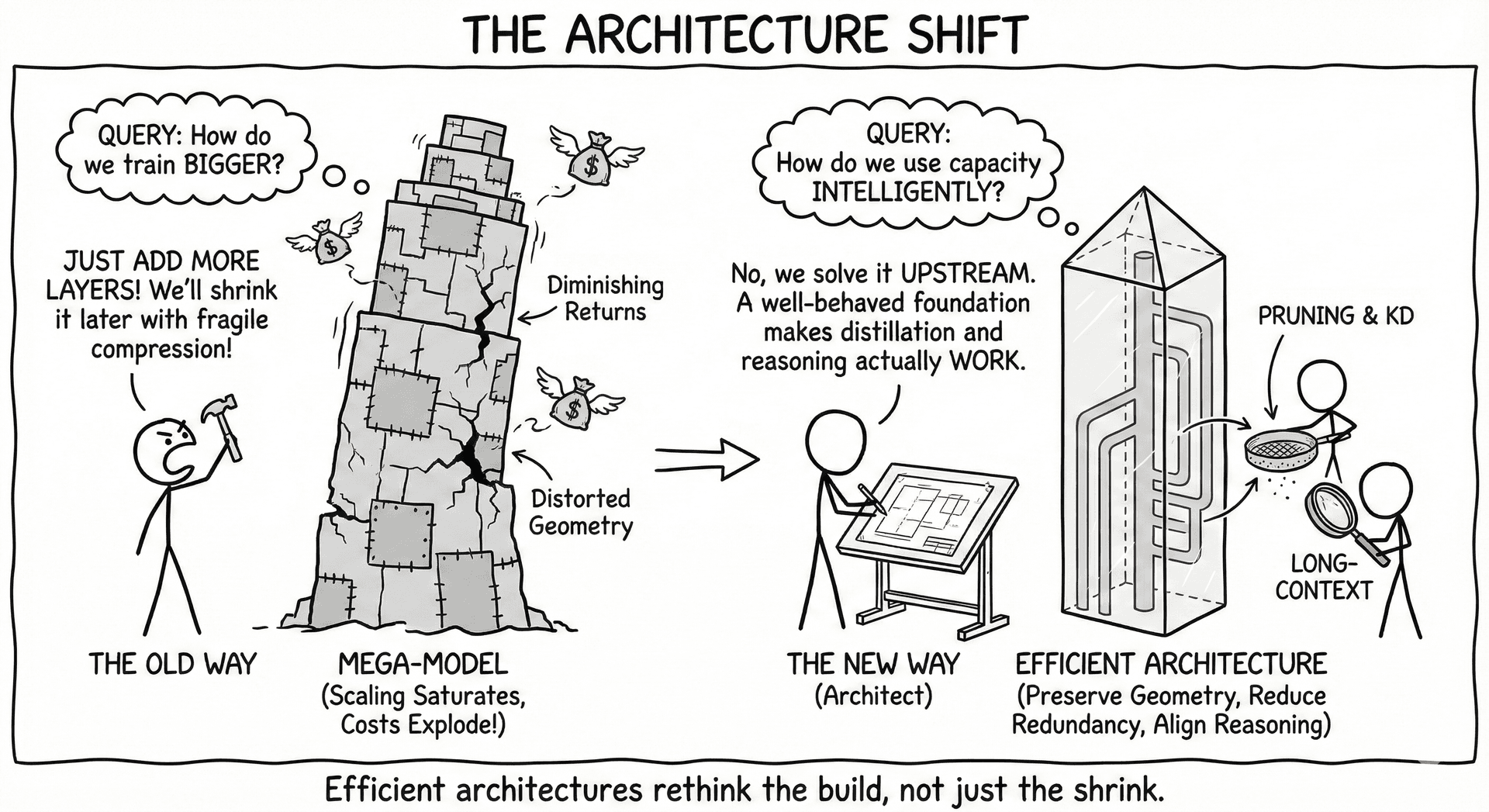
Efficient architectures rethink how LLMs should be built, not just shrunk. As scaling saturates and costs explode, the question is no longer “How do we train bigger models?” but rather “How do we design models that use capacity intelligently?” Our work shows that architectural efficiency emerges from preserving geometry, reducing redundancy, aligning reasoning paths, and enabling predictable downscaling.
Why We Need Efficient Architecture
- Bigger models don’t always generalize better; scaling laws show diminishing returns and rising cost.
- Vanilla Transformers distort manifold geometry, forcing unnecessary width/depth.
- Distillation improves accuracy but often breaks reasoning fidelity, exposing structural inefficiencies.
- Compression is fragile when architectures lack pruning-friendly or value-aware structure.
- Efficient architectures solve these problems upstream, letting pruning, KD, and long-context inference operate on a well-behaved foundation.
How Our Works Connect the Dots
- TransJect (Manifold-Preserving Transformers) — shows that preserving geometric structure reduces representational waste and enables shorter, more stable networks.
- PruneNet (Calibration-Free Structured Pruning) — demonstrates that architectures should expose spectral structure so pruning can be done once, without data or calibration.
- Downscaling Laws — provide theoretical grounding for models that shrink gracefully, supporting efficient ensembles and pruning-aware designs.
- Generalization vs Fidelity Paradox in KD — reveals that architecture must support fidelity-preserving training, not just accuracy gains.
- Collaborative KD — shows how teacher–student architectures co-adapt, reducing brittleness and improving sample efficiency.
- Scaling Law Survey — situates all these results within a broader theory of how architectures should be shaped to scale up and down reliably.
Together, these works present a unified view: efficient architecture is a geometric, algorithmic, and systems-level principle—not a post-hoc optimization trick.
Practical Guide — Which Paper to Use When?
- If your model struggles with long-range signals or unstable representations → Manifold-Preserving Transformers (TransJect).
- If you want structured pruning without calibration data → PruneNet.
- If you want predictable shrinkability and compute-performance tradeoffs → Downscaling Laws.
- If KD improves accuracy but breaks reasoning behaviors → Generalization vs Fidelity Paradox.
- If you need robust teacher–student co-training → Collaborative KD.
- If you want theory for model size, data scaling, and architectural choices → Scaling Law Survey.
Big Picture
Efficient architectures are not about making small models—they are about making smart structures that preserve geometry, reason reliably, compress cleanly, and adapt across scales. Our research shows that the path to practical LLMs is not “more parameters,” but better-designed ones.